How I Trained a High-Performance Coding Model on a Single GPU
Meet Anni: a 14B parameter coding LLM built on a student budget. Using progressive training and data distillation on a single GPU, we overcame hardware limits to achieve SOTA-tier efficiency and performance.

In the rapidly evolving landscape of Artificial Intelligence, the development of Large Language Models (LLMs) has been characterized by an exponential increase in parameter size and computational requirements. Researchers in academic settings often face resource constraints — a significant hurdle often described as the "Hardware Limitations". Modern State-of-the-Art (SOTA) models typically possess parameter counts ranging from 700B to 1.6T, making them prohibitively expensive to train from scratch.
For instance, even training a standard 7-billion parameter model requires processing trillions of tokens and utilizing cluster-scale computing resources (e.g., thousands of H100 GPUs), a feat effectively impossible for individual academic labs or students. Furthermore, the complexity of managing Linux environments—handling dependencies, GPU drivers, and long-running processes—adds another layer of difficulty to the development pipeline.
This resource constraint necessitates a strategic shift: moving away from "training from scratch" towards intelligent fine-tuning. This report details the development of Anni, a 14-billion parameter LLM specialized in Data Structures and Algorithms (DSA). By leveraging efficient optimization frameworks and high-quality synthetic data, we demonstrate that academic resource constraints do not preclude competitive, high-performance. Our model achieves coding proficiency comparable to proprietary industry leaders, challenging the assumption that frontier-level capabilities require cluster-scale compute.

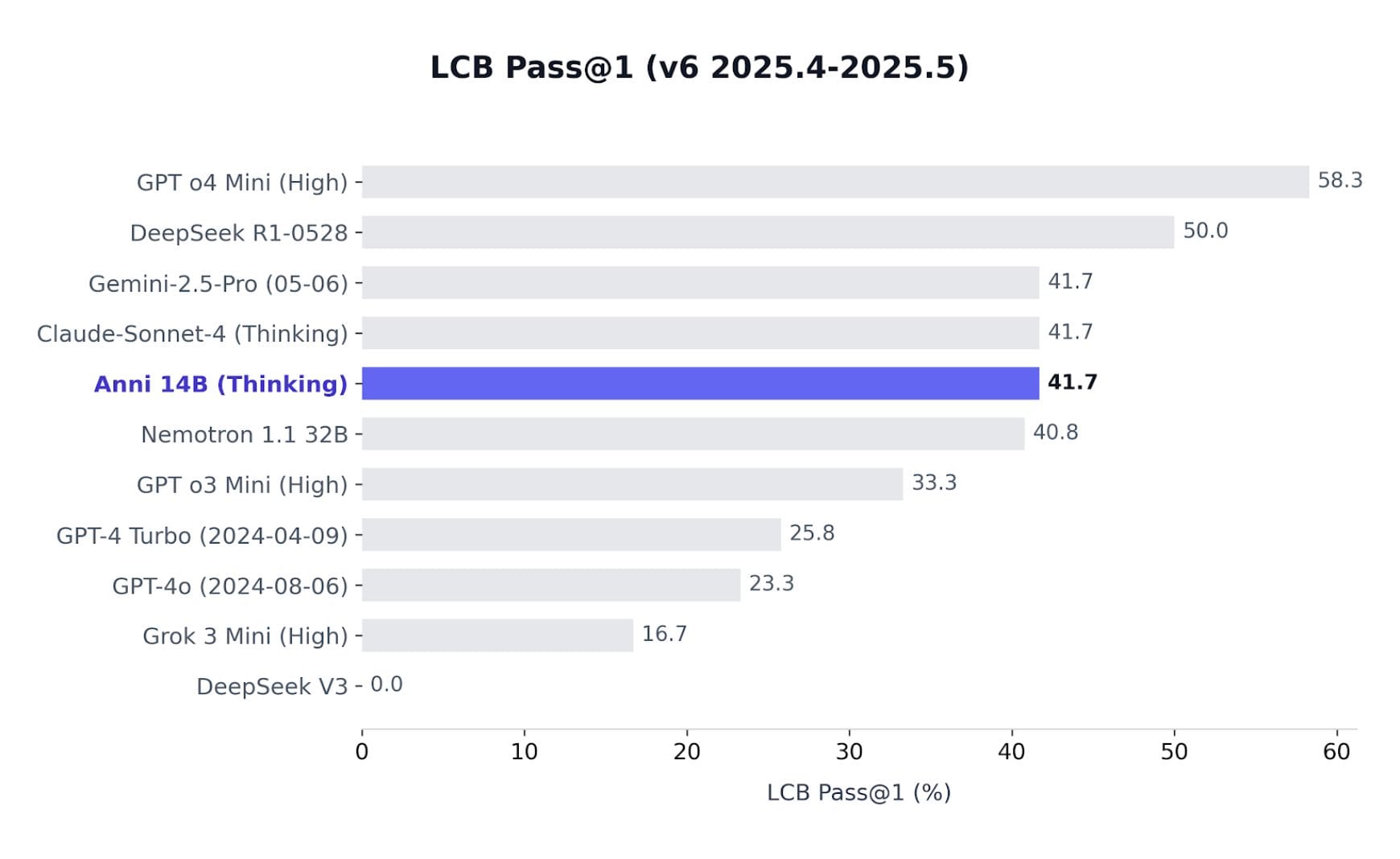
LiveCodeBench v6 benchmark result
See possible contamination note below


⚠️ A Critical Note on Data Contamination
While these results look incredible—matching Claude 3.5 Sonnet and beating GPT-4o—we must address the timeline specifics that likely skew the results.
- Benchmark Cutoff: The LiveCodeBench (v6) subset used for this evaluation only contains questions up to May 2025. It does not include any "future" problems released after that date, preventing us from testing the model on truly unseen data.
- Dataset Overlap: The Nvidia OpenCodeReasoning-2 training dataset was curated between March 2025 and May 2025. While the majority of this training data consists of older historical problems (pre-2025), the curation window perfectly overlaps with the April–May 2025 questions used in the benchmark.
This creates a confirmable data leakage, meaning the model likely "saw" the specific test questions (or their immediate variations) during training.
- Does this model beat GPT-4o on generalization? Unlikely.
- Does it demonstrate that a student can train a model to perfectly internalize complex logic on a single GPU? Absolutely.
Future Verification: To address this, we plan to re-benchmark Anni immediately upon the release of LiveCodeBench v7 (covering post-June 2025 questions). This will provide a clean, uncontaminated test set to definitively verify the model's true generalization capabilities.
2. Background
The development of Anni relied on making critical architectural decisions early in the process, specifically regarding the choice of the base model and the optimization techniques required to run it on consumer-grade hardware.
2.1 Base Model Selection: Why Qwen?
Selecting the appropriate foundation model was paramount to the project's success. While popular families such as Llama were considered, we ultimately selected the Qwen 3 architecture (specifically the 14B parameter variant) as our base.
This decision was driven by two primary factors:
-
Superior Coding Benchmarks: As illustrated in the benchmark comparison below, the Qwen architecture demonstrates exceptional performance in coding tasks compared to its peers. In competitive programming evaluations such as CodeForces (Elo Rating) and LiveCodeBench, Qwen models consistently outperform similarly sized models, providing a stronger starting foundation for our DSA-focused fine-tuning.
-
Multi-Language Support (Chinese): Unlike the Llama series, which is heavily optimized for English, Qwen boasts robust native support for multiple languages, including Chinese. Although our fine-tuning dataset was primarily English-based, starting with a base model proficient in Chinese ensures that Anni retains the capability for cross-lingual reasoning and potential future adaptation for Chinese DSA instructions.

2.2 Technical Constraints and Solutions
To fine-tune a 14B model on limited hardware (specifically an Nvidia A6000), we had to overcome significant VRAM limitations. A full fine-tune of a 14B model would typically require immense memory for gradients and optimizer states.
To address this, we utilized Unsloth, an open-source framework designed to optimize the fine-tuning pipeline. This allowed us to employ QLoRA (Quantized Low-Rank Adaptation) and 4-bit Normal Float (NF4) quantization. By loading the base model in 4-bit precision, we reduced the memory footprint for weights by a factor of 4, bringing the VRAM requirement down to approximately 7 GB for the base weights (14B × 0.5). This optimization was critical in allowing us to fit the training process within the 48GB VRAM buffer of our available hardware.
2.3 Low-Rank Adaptation (LoRA) Configuration
To make fine-tuning feasible on our hardware, we employed Low-Rank Adaptation (LoRA). Instead of updating the full weight matrix W during training—which would be computationally prohibitive—LoRA freezes the pre-trained model weights and injects two smaller trainable matrices, A and B, into each layer. The weight update is then represented as Delta W = BA, significantly reducing the number of parameters that need to be stored in VRAM.
For Anni, we targeted the following linear layers for adaptation: q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, and down_proj. By optimizing the rank r and alpha a parameters, we were able to reduce the number of trainable parameters to less than 1% of the total model size, leaving the vast majority of the 14B model frozen.
3. Challenges Faced
3.1 Hardware Limitations and the Challenges of Scale
Researchers in academic settings often face resource constraints. Modern State-of-the-Art (SOTA) models possess parameter counts ranging from 7B to 70B. Processing the massive unstructured data required to train these models is difficult to complete efficiently through human labor alone.
For example, training a 7-billion parameter model from scratch requires trillions of tokens and cluster-scale computing (e.g., thousands of H100 GPUs), which is effectively impossible for academic labs or individual students. Furthermore, managing the Linux environment—handling dependencies, GPU drivers, and long-running processes via tools like tmux—adds another layer of complexity. This resource constraint necessitates a shift in strategy: from "training from scratch" to "intelligent fine-tuning" and "AI-assisted development."
3.1.1 Solution Architecture: Unsloth, QLoRA, and Flash Attention
To overcome this, I utilized Unsloth (https://unsloth.ai/), an open-source framework that optimizes the fine-tuning pipeline. The optimization strategy involves three key AI-driven technologies:
- 4-bit Normal Float Quantization (NF4):
I utilized the QLoRA (Quantized Low-Rank Adaptation) technique. By loading the base model in 4-bit precision (using the bitsandbytes library), the memory footprint for weights is reduced by a factor of 4.
(14B × 0.5) ~ 7GB

This fits comfortably within VRAM, leaving space for activations. However, this still doesn't take context size and other things into account.
- Low-Rank Adaptation (LoRA):
Instead of updating the full weight matrix W, LoRA freezes W and injects two smaller trainable matrices A and B, such that the weight update is Delta W = BA.


In my experiment, I targeted the q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, and down_proj modules. By setting the rank r=16 and alpha=16, I reduced the trainable parameters to less than 1% of the total model size.
In my experiment, I targeted the q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, and down_proj modules. By setting the rank r=16 and alpha=16, I reduced the trainable parameters to less than 1% of the total model size.
config.yaml

train.py

However, some VRAM saving tricks were deliberately NOT chosen; for example, gradient_checkpointing , as it slows down training by recomputing activations. With 48GB of VRAM available (thanks to the A6000 GPU), faster throughput was prioritized over unnecessary memory conservation.
Gradient Checkpointing: Reduces memory usage by dropping intermediate activations and re-calculating them during the backward pass (backward propagation). This saves GBs of VRAM but usually slows down training by 20-30%.
- Parameter Selection:
For the LoRA configuration, we selected a rank of
r=32and an alpha ofalpha=64.
While standard text fine-tuning tasks often utilize lower ranks (e.g., r=8 or r=16), the complexity of code generation requires the model to internalize rigorous syntactic structures and logical dependencies. By increasing the rank and alpha, we expanded the capacity of the trainable adapters, allowing the model to capture these intricate patterns more effectively without the computational overhead of a full fine-tune.
For
temperature,min_p,top_p, andtop_kparameters, we opted to follow Qwen's recommended settings

For context
max_sequence_length32000 was chosen because it allows the model to process over 99.9% of the dataset without truncation, ensuring that the full logical context of complex, long-form coding solutions is preserved during training. (See Figure 3.5.1.3)
Training hyperparameters:
Effective batch size (
per_device_batch_size*gradient_accumulation):
-per_device_batch_size= 1
-gradient_accumulation= 16
Due to VRAM constraints, per_device_batch_size is set to 1 so that the model can be trained on 32000 context length (max_seq_length).
Effective batch size (EBS) = 16

The remaining hyperparameters largely align with Unsloth's official fine-tuning presets (see Figure 3.1.1.3.4). However, distinct deviations were made for dynamic parameters—specifically weight_decay, early_stopping, and test_ratio—which were adjusted per training stage (methodology detailed in Section 3.5.1).
Learning Rate & Steps: I selected a conservative learning_rate (2e-5 for stages 1-3 and 1e-5 for stage 4) to ensure stability and prevent catastrophic forgetting given the large volume of training rows. Furthermore, rather than training for a rigid number of epochs, the training duration was controlled via max_steps in conjunction with an Early Stopping mechanism. This allowed the model to halt training automatically once convergence was reached, optimizing the "value-wise" performance.

Scheduler Configuration: The lr_scheduler_type was adapted to fit the curriculum strategy:
-
Stages 1–3: A
cosineschedule was utilized. This allows for smoother convergence by maintaining higher learning rates for longer periods in the middle of training before tapering off, which is effective for the initial broad adaptation phases. -
Stage 4: A
lineardecay was adopted to ensure a steady, consistent reduction in the learning rate. This provided a stable finishing trajectory as the model "tied everything together" on the full 32k context window without the curvature of a cosine schedule.


hyperparameter recommendations (Source: https://docs.unsloth.ai/get-started/fine-tuning-llms-guide/lora-hyperparameters-guide#hyperparameters-and-recommendations)3.2. Choosing a coding dataset
A critical bottleneck in training code-generation models is the scarcity of high-quality, executable code examples that are distinct from the training data of the base model. We conducted an extensive search regarding high quality competitive programming datasets and decided to use Nvidia’s OpenCodeReasoning-2 dataset.
Their dataset methodology works as follows:
-
Source Acquisition: They scrape programming questions from competitive coding websites such as
Codeforces. There are millions of these questions, often with complex edge cases and time-complexity constraints. -
AI Generation: Instead of relying on human programmers to solve them, they utilize a high-capacity "Teacher Model" (in this case,
Deepseek R1) to generate answers to the problems. -
Automated Unit Testing: This is the crucial innovation. They automate unit tests to check the execution of the generated code against the problem's requirements. The result is stored in a
pass_ratecolumn.


This technique is best described as Synthetic Data Generation with Automated Verification.
From my experience analyzing these datasets, this approach allows for "Data Distillation." By filtering for a high pass_rate (e.g. only keeping solutions that pass 100% of unit tests), we refine the dataset to ensure it ONLY contains 100% correct, high-quality input data that has passed all test cases. Having high-quality input datasets explains how open-source LLMs with low parameter counts, such as Qwen 3 4B or Llama 3 8B, can effectively "punch above their weight," matching or beating SOTA models from just a year ago. They are generally trained on data that is cleaner than the web-scraped data used by their predecessors.
3.3 Infrastructure Stability
Given the remote nature of the training infrastructure (Nvidia A6000 accessed via SSH), maintaining persistent training sessions was critical. To mitigate the risk of connection timeouts terminating active processes, all training routines were executed within a detached tmux session. This ensured that long-running epochs continued uninterrupted even during network instability or client-side disconnections.


train.sh script showcasing how tmux is used to maintain a persistent training session even after disconnecting the `ssh` session3.4 Nvidia-OpenCodeReasoning2 dataset is missing the question column
A review of the OpenCodeReasoning-2 dataset revealed that the question column was intentionally left blank for a significant portion of the data. This omission is a compliance measure regarding data licensing. As shown in the dataset's source and license columns (See Figure 3.4.2), the content is aggregated from multiple platforms with varying legal restrictions.

question column
source and license columnsWhile questions from platforms like Codeforces and CodeChef are generally released under the permissive Apache 2.0 license, other sources utilize the slightly more restrictive CC-BY 4.0 (Creative Commons) license. The dataset authors necessitate that users retrieve this content directly from the original source to respect these terms.

To resolve this, we implemented a custom scraping pipeline (preprocess.py) to reconstruct the dataset. This script systematically queried the original URLs to populate the missing question fields, ensuring we had a complete training corpus while maintaining strict adherence to the respective source licenses.

3.5 Long Training times (~ 1200 hours)

The tqdm projection above indicated a single-epoch duration of ~598 hours, resulting in an estimated total runtime of 1.64 months prior to the implementation of progressive training optimizations.

3.5.1 Optimizations and Compromises
1. Use early stopping
Early stopping is a regularization strategy used to optimize the training of iterative machine learning models. Rather than running for a predetermined number of epochs, this technique continuously monitors the model's performance on a held-out validation set. The training process is automatically terminated once the validation metric stops improving or begins to degrade, thereby preventing overfitting and ensuring computational resources are not wasted on diminishing returns.
Early stopping is primarily a technique to prevent overfitting but that wouldn't be the case in our scenario because we have 74,232 rows of data which is more than enough for the model's SFT training. If we only go through the data for one epoch, theoretically, the model should not overfit as long as the competitive programming questions are not that similar to each other.

pass_rate in Nvidia's OpenCodeReasoning-2 python split datasetIn our case, we used early stopping to preemptively stop our training once diminishing returns kicks in.

train.pyOur early-stopping setup is configured to stop training once the evaluation loss stays within the early_stopping_threshold for early_stopping_patience successive evaluations.
The early_stopping_patience is set to 4 and early_stopping_threshold is set to 0.002 for the first three stages. For the fourth stage, we decided to not utilize early stopping and instead trained for a max_steps of 1000.
While a low evaluation loss is not a perfect representation of coding capability, we utilized it as a heuristic to minimize training time.
2. Progressive Training
Progressive Training is an optimization strategy where the complexity of the training task is gradually increased over time. Instead of training on the full architecture or maximum data dimensions immediately, the model begins with reduced specifications—such as shorter sequence lengths, lower image resolutions, or fewer active layers. By allowing the model to learn fundamental patterns under lighter computational loads first before scaling up, this method accelerates convergence, improves stability, and significantly reduces overall training time and cost.
To inform our progressive scaling strategy, we first analyzed the distribution of token lengths within the dataset's r1_generation column. As seen in the histogram below, the data is heavily skewed, with 90% of samples containing fewer than ~14,000 tokens.
Data Histrogram

Distribution Tables
1. Key Metric
| Metric | Value |
|---|---|
| Count | 95,786 |
| Mean | 7,079.83 |
| Std Dev | 4,636.21 |
| Min | 365 |
| Median | 6,138 |
| Max | 64,861 |
2. Percentiles
| Percentile | Value |
|---|---|
| 25% | 3,215 |
| 50% (Median) | 6,138 |
| 75% | 10,224 |
| 90% | 13,945.50 |
| 95% | 15,693.00 |
| 99% | 19,125.15 |
| 99.9% | 23,550.59 |
| Max (100%) | 64,861 |
Based on these distinct distributional clusters, the training process was structured into four distinct stages to optimize computational efficiency.
- The first stage is primarily to teach the model fundamental patterns and syntax using the high-frequency "easy" data (0–4096 tokens), maximizing training speed where the majority of the dataset lies.
Train stats:

Eval stats:

GPU Stats:

- The second stage is to adapt the model to "medium-hard" contexts (4097–13946 tokens) , enabling it to grasp paragraph-level dependencies and longer logical structures. A
max_seq_lengthof13946tokens is chosen since it's located at the 90% percentile.
Train Stats:

Eval Stats:

GPU Stats:

The context length for the second stage spans from 4,097 to 13,946 tokens.
- The third stage is to fine-tune on "extremely hard" long-context examples (13947–32000 tokens), forcing the model to handle computationally expensive, long-range dependencies found in the tail end of the data distribution.
Due to time constraints, the third stage training was limited to 200 steps.
Train Stats:

Eval Stats:
1. 100th step:

2. 200th step:

GPU Stats:

- The fourth stage is to tie everything together by training on the full sequence range with a reduced learning rate (1e-5) and weight decay, ensuring the model retains short-context performance while stabilizing its long-context capabilities.
Train Stats:

Eval Stats:

GPU Stats:

Observations:
- The context length of
r1_responseoutput may not be a strong indicator of problem difficulty may have a strong correlation with it. - Wandb.ai was used as the logging/monitoring solution. All graphs during each training stage above are generated using Wandb (Weights and Biases).
- Training Continuity: The discontinuities observed in the visualized metrics (gaps in the graphs) reflect intermittent resource availability. Training sessions were subject to preemption and scheduled pauses due to shared GPU access constraints, necessitating the robust checkpointing and resumption workflow described in Section 3.3.
Overall, by employing early stopping and progressive training, we are able to cut down our training times from an expected continuous training time of 1.64 months to around 1-2 weeks, achieving a 77.13% reduction in computational runtime and accelerating the model development pipeline.
3.6 Retroactive Data Deduplication and Training Integrity
As we advanced to Stage 4, designed to unify the model's capabilities across the full (0–32k) token range, maintaining training integrity became paramount. A critical risk in multi-stage curriculum learning is "data leakage," where the final convergence stage accidentally retrains on "easy" or "medium" samples already mastered in previous epochs, leading to overfitting rather than generalization.
Since our dataset loaders utilized deterministic seeding seed=42, a standard initialization for Stage 4 would have inevitably re-served the exact same starting samples used in Stages 1–3. To prevent this and guarantee that Stage 4 provided a strictly novel learning signal, we designed and implemented a Retroactive Data Deduplication Pipeline.
The Solution: Retroactive Simulation and Hashing
To ensure Stage 4 trained exclusively on fresh, unseen data, we implemented a retroactive simulation pipeline to identify and exclude previously used samples.
1. Content-Based Hashing (Immutable IDs) To track data usage reliably across different training configurations, we moved away from mutable row indices. Instead, we implemented a content-based hashing strategy, generating a unique MD5 identifier for every sample in the dataset based on its text content.

2. Simulation of Stages 1-3 We wrote a script to simulate the data loading process for the first three stages. By running the load_and_tokenize function with the exact parameters used previously (e.g., max_seq_length limits and sample counts), we collected the unique_ids of every sample the model had already seen.

3. Set Subtraction (O(n) Filtering) With the used_ids collected in memory, we applied a set subtraction operation to the Stage 4 dataset. This filter rigorously removed any sample whose ID existed in the usage history, ensuring that every token processed in the final stage represented fresh, unseen data.

4. Dynamic Validation Resampling The simulation revealed that the deterministic validation set had been fully exhausted during the earlier curriculum stages, which would have resulted in StopIteration errors and zero visibility into validation loss. To address this, the pipeline included logic to detect empty validation sets and automatically trigger a dynamic re-splitting process. The system merged remaining data and carved out a new 5% split from the fresh Stage 4 corpus, ensuring the model had a valid, unseen reference for evaluation.

By making these adjustments, we guaranteed that Stage 4 provided a novel learning signal to the model, rather than just reinforcing rote memorization of previous stages.
3.7 Unsloth Bug (Unable to merge to 16-bit and export as GGUF)
During the final export phase, a critical issue was encountered where the fine-tuned adapter could not be merged into the base model for 16-bit GGUF conversion.
The Issue: The adapter_config.json generated by Unsloth automatically saved the base_model_name_or_path as an absolute local directory path pointing to the specific cache location on the training machine (e.g., /mnt/storage/metnet/coding_llm/.cache/...) rather than the Hugging Face Hub repository ID.

This caused the merging script to fail because it attempted to resolve the base model from a specific local path that was either inaccessible during the inference setup or incompatible with the merge logic, which expects a standard model identifier.
The Fix: To enable the merge and GGUF export, the configuration file required manual intervention to point back to the upstream model repository.
-
Retrieve Original Model: Manually identified and pulled the base model architecture from the Hub. This ensures the merge script has immediate access to the correct weight initialization before attempting to combine the adapters.
-
Locate the Config: Opened
adapter_config.jsoninside the fine-tuned checkpoint folder (32000_finetuned_model). -
Edit the Path: Replaced the hardcoded local path with the correct Hugging Face Hub identifier.
- Original (Broken):
"base_model_name_or_path": "/mnt/storage/metnet/.../unsloth/qwen3-14b-unsloth-bnb-4bit"

- Corrected:
"base_model_name_or_path": "/mnt/storage/metnet/.../unsloth/qwen3-14b"

By forcing the config to reference the remote repository, the merging script was able to correctly re-download (or verify) the original architecture and successfully merge the LoRA adapters for the final GGUF export.
save.py

4. Inference and Deployment
Once the model is fine-tuned and exported, we implemented multiple serving strategies to address different use cases ranging from development testing to user-facing deployment. We first upload the model to huggingface and modelscope via this upload script and via git lfs as a fallback.
upload.py

Huggingface
- VLLM - https://huggingface.co/BigJuicyData/Anni
- GGUF (Q4_K_M) - https://huggingface.co/BigJuicyData/Anni-Q4_K_M-GGUF
- MLX (4-bit) - https://huggingface.co/BigJuicyData/coder-final-mlx-4Bit
Modelscope
4.1 Direct Code Integration (Native & Unsloth)
For immediate testing and development loops, the model is served directly within a Python environment using the Unsloth/Hugging Face ecosystem. This method allows for maximum control over generation parameters (temperature, top_k) and is ideal for debugging model outputs programmatically.
-
Method: We utilize the
FastLanguageModelclass to load the adapter and base model. -
Implementation: As seen in the figure below, the inference pipeline handles tokenization, chat template application, and tensor movement to the GPU.

FastLanguageModel.4.2 Quantized Local Inference (GGUF & llama.cpp)
To enable efficient inference on hardware with limited VRAM (or for the exported GGUF format mentioned in Section 3.6), we utilized llama-cpp-python. This acts as a Python binding for llama.cpp, allowing us to load the 4-bit or 16-bit GGUF models efficiently.
-
Setup: The environment detects the CUDA version (12.4) and installs pre-built binaries to ensure GPU acceleration is enabled for the quantized model.
-
Use Case: This method is preferred for local deployment or "edge" serving where loading the full uncompressed weights is not feasible.
Anni GGUF Inference Demo

The PROMPT variable serves as a placeholder, designed to be substituted with the user's specific programming inquiry during execution.

PROMPT variable4.3 Production Serving (vLLM + Frontend) [Free + Paid Approaches]
For a scalable, user-friendly experience, we deployed the model using vLLM (a high-throughput and memory-efficient inference engine) paired with a web frontend.
- Architecture: vLLM manages the memory efficiently using
PagedAttention, allowing for higher concurrency than standard Hugging Face pipelines. This backend is then exposed via an API to a frontend interface (such asGradioorStreamlit), simulating a "ChatGPT-like" experience for the end-user.
To make the vLLM demo easily accessible, users are encouraged to use the provided vLLM Serve Demo and configure the web frontend to get started.
Anni VLLM Serve Demo

vllm and bitsandbytes library installation.4.3.1 Bridging Google Colab with Ngrok
Since Google Colab instances operate within isolated containerized environments without static public IP addresses, external applications (such as our local web frontend) cannot directly access the vLLM server running inside the notebook.
To solve this, we utilize ngrok, a cross-platform application that establishes secure tunnels to localhost. This exposes the vLLM inference server (running on port 8000 inside Colab) to a public internet URL.
Ngrok is a simplified reverse proxy tool that establishes a secure tunnel from a public endpoint to a locally running network service. In the context of Google Colab, instances are hosted in isolated virtual containers behind network address translation (NAT) and firewalls, meaning they do not have static public IP addresses accessible from the outside internet. Ngrok bridges this gap by exposing the inference server (running on
localhost:8000) to a public URL (e.g.,https://random-id.ngrok-free.dev), allowing external applications—such as our web frontend—to send API requests to the model securely.
Setup Workflow:
- Account Creation: Users must sign up for an ngrok account to obtain a unique authorization credential.

2. Token Configuration: As shown in the figure below, the user must copy their Authtoken from the ngrok dashboard and add it to the Google Colab secrets manager (or input it directly).

Authtokens section webpage.
Secrets sidebar configuration.3. Agent Deployment: The notebook installs the ngrok agent, authenticates using the token, and creates a tunnel.

Once the agent is running, it generates a forwarding URL (e.g., https://<random-id>.ngrok-free.dev) visible in the "Agents" section of the dashboard or the Colab output.
4.3.2 Frontend Integration
With the public endpoint active via ngrok, the final step enables the user interface to communicate with the remote vLLM backend. The frontend application is built using Next.js and requires a local initialization to connect to the tunnel.
1. Installation & Dependencies First, the repository was cloned locally and the necessary Node.js dependencies were installed. This sets up the web server environment required to render the chat interface.
# Clone the repository and navigate to the web directory
git clone https://github.com/CoderUni/Anni.git
cd Anni/web
# Install dependencies
yarn install
2. Environment Configuration The core integration relies on linking the local frontend to the remote ngrok tunnel. Navigate to the Anni/web directory and rename the template file .example.env to .env and modified the connection parameters.
Crucially, the VLLM_URL variable must be updated to match the public URL generated by ngrok in the previous step, replacing the default localhost address.
-
VLLM_URL: The public ngrok endpoint (e.g.,
https://<id>.ngrok-free.dev). Paste thengrokURL into theVLLM_URLvariable. -
VLLM_MODEL: The specific model identifier matching the backend config.
-
VLLM_TOKEN_LIMIT: Adjusted to
32000to utilize the full context window.

.env file that has yet to have its variables set and name renamed from example.env to .env3. Deployment Once configured, the development server was launched using yarn dev. The interface becomes accessible at http://localhost:3000, providing a chat-based UI that routes user prompts through the ngrok tunnel to the Colab-hosted model.
Anni VLLM Web Frontend

Anni web interface running locally, capable of retrieving algorithmic responses from the fine-tuned model.4.4 (Paid) Serving with Vast.ai
For users requiring a robust, always-on deployment without the constraints of free-tier notebooks (e.g., session timeouts or GPU unavailability), we recommend deploying the model on Vast.ai. This marketplace allows users to rent high-performance GPUs at competitive rates, making it an ideal solution for hosting the 14B model with its 32k context window.
Deployment Procedure:
1. Instance Provisioning: Users can swiftly provision a compatible GPU instance (minimum 48GB VRAM required) using our pre-configured template.
* Referral Link: Rent GPU on Vast.ai
* Template: Anni vLLM Template

2. Accessing the API: Once the instance is successfully initialized and running, users must open the instance portal to retrieve the public endpoint.

As shown in the example URL below, the endpoint contains both the base URL and the authentication token:
https://snapshot-rom-logan-analog.trycloudflare.com/docs?token=15363a440cb2a9962b854d5e89e00d7ae2283fdf2dd0613352e848f90f7fc0a7

3. Frontend Configuration: To connect the web interface to this paid instance, the retrieved URL must be parsed into its base domain and API key components. These values are then populated in the .env configuration file of the frontend application:
# .env Configuration for Vast.ai Serving
NEXT_PUBLIC_VLLM_URL="https://snapshot-rom-logan-analog.trycloudflare.com"
VLLM_API_KEY="15363a440cb2a9962b854d5e89e00d7ae2283fdf2dd0613352e848f90f7fc0a7"

With these credentials configured, the frontend can be deployed on hosting services such as Render or Railway, providing a stable, production-grade access point to the Anni model.
5. Limitations
While the Anni model demonstrates strong performance in algorithmic reasoning and code generation, several limitations remain due to architectural constraints, scope, and training resource trade-offs.
5.1 Domain and Language Specificity
The model was fine-tuned exclusively on a corpus of English instructions focused on Data Structures and Algorithms (DSA) in Python.
-
Language Rigidity: While the base model (Qwen) is multilingual, the aggressive fine-tuning on English data may have degraded its performance in other languages (e.g., Chinese instructions), a phenomenon known as catastrophic forgetting.
-
Syntax Specialization: The model is optimized for Python syntax. It may struggle or hallucinate syntax if queried for solutions in other programming languages like C++, Java, or Rust, as the specialized weights are biased toward Pythonic paradigms (e.g., list comprehensions, dynamic typing).
5.2 Model Scale and Hallucinations
At 14 Billion parameters, the model occupies a "mid-sized" tier in the current LLM landscape.
-
Reasoning Depth: While sufficient for standard LeetCode-style problems, 14B parameters may lack the deep reasoning capabilities required for complex system design questions or highly obscure mathematical proofs found in larger models (70B+).
-
Knowledge Cutoff: Unlike web-connected frontier models, this model relies solely on its static internal weights. It may hallucinate nonexistent libraries or deprecated Python functions when faced with edge cases outside its training distribution.
5.3 Benchmark Scope and Potential Contamination
The performance metrics cited in this report rely on a specific temporal slice of LiveCodeBench (v6) covering the April–May 2025 window. This evaluation is subject to two critical limitations:
-
Sample Size: The evaluated subset contains approximately 12 questions, a sample size too small to establish statistical significance or broad generalization. The reported Pass@1 score of 41.7% should be interpreted as a snapshot of performance on this specific problem set rather than a definitive SOTA claim across all coding tasks.
-
Temporal Overlap: The Nvidia OpenCodeReasoning-2 dataset was curated between March 2025 and May 2025. As this overlaps with the benchmark's problem release window, there is a non-zero probability of data leakage, where the model may have been exposed to these specific competitive programming problems during fine-tuning.
5.4 Training Depth vs. Efficiency Trade-off
To optimize for the 48GB VRAM constraint and reduce training time from ~1.6 months to ~2 weeks, we employed Early Stopping and did not complete a full epoch over the entire dataset.
-
Under-fitting Risk: While the model converged to a "good enough" value-wise performance, it has not theoretically maximized its potential. The model may exhibit instability on the "long-tail" of harder examples that were seen less frequently (or not at all) during the shortened training cycle.
-
Long-Context Granularity: Due to the progressive training schedule, the model spent less time training on the maximum context length (32k) compared to shorter sequences. Performance on extremely long prompts (e.g., pasting an entire codebase) may be less robust than performance on short function snippets.
5.5 Deployment Latency (Only applies to FREE version)
The free version of serving architecture—relying on a Google Colab backend tunneled via ngrok—introduces inherent latency.
-
Network Bottlenecks: The reliance on a reverse proxy adds round-trip time (RTT) to every request.
-
Cold Starts: As a non-commercial deployment, the model is subject to compute preemption and is not suitable for real-time, low-latency production environments.
6. Conclusion
The development of Anni represents a significant case study in overcoming the hardware constraints that often stifles academic AI research. By shifting our strategy from resource-intensive pre-training to intelligent fine-tuning, we successfully adapted a 14-billion parameter Qwen model into a SOTA-class coding assistant using a single Nvidia A6000 GPU.
Performance Validation:
Empirical results from LiveCodeBench (v6) show Anni achieved a Pass@1 score of 41.7% on the evaluated subset. While this score matches massive proprietary models like Claude-Sonnet-4 (Thinking), it is important to note that this represents a specific temporal slice where training data and test questions likely overlapped. However, the fact that a 14B model could perfectly internalize this logic with such high efficiency is a testament to the power of data distillation.
Future Verification:
To address the potential data contamination, we plan to re-benchmark Anni immediately upon the release of LiveCodeBench v7 (covering post-June 2025 questions). This will provide a clean, uncontaminated test set to definitively verify the model's true generalization capabilities.
Methodological Success:
This achievement was driven by two key technical innovations:
-
Data Distillation: Leveraging the Nvidia OpenCodeReasoning-2 dataset ensured the model learned from verified, error-free logic rather than noisy web scrapes.
-
Progressive Training & Early Stopping: Structuring the curriculum to prioritize shorter sequences before scaling reduced training time by 77.13% (from 1.64 months to ~2 weeks) without sacrificing "value-wise" convergence.
While limitations regarding language specificity and deployment latency remain (see Section 5), the project has exceeded its primary objective. Anni stands not just as a proof-of-concept for efficiency, but as a legitimate competitor in the coding LLM landscape, demonstrating that SOTA performance is possible and accessible to students and researchers outside of top-tier industrial labs.